OpenAI
@OpenAI
Introducing EVMbench—a new benchmark that measures how well AI agents can detect, exploit, and patch high-severity smart contract vulnerabilities. https://t.co/op5zufgAGH
1.3kretweets
View on X· Updated
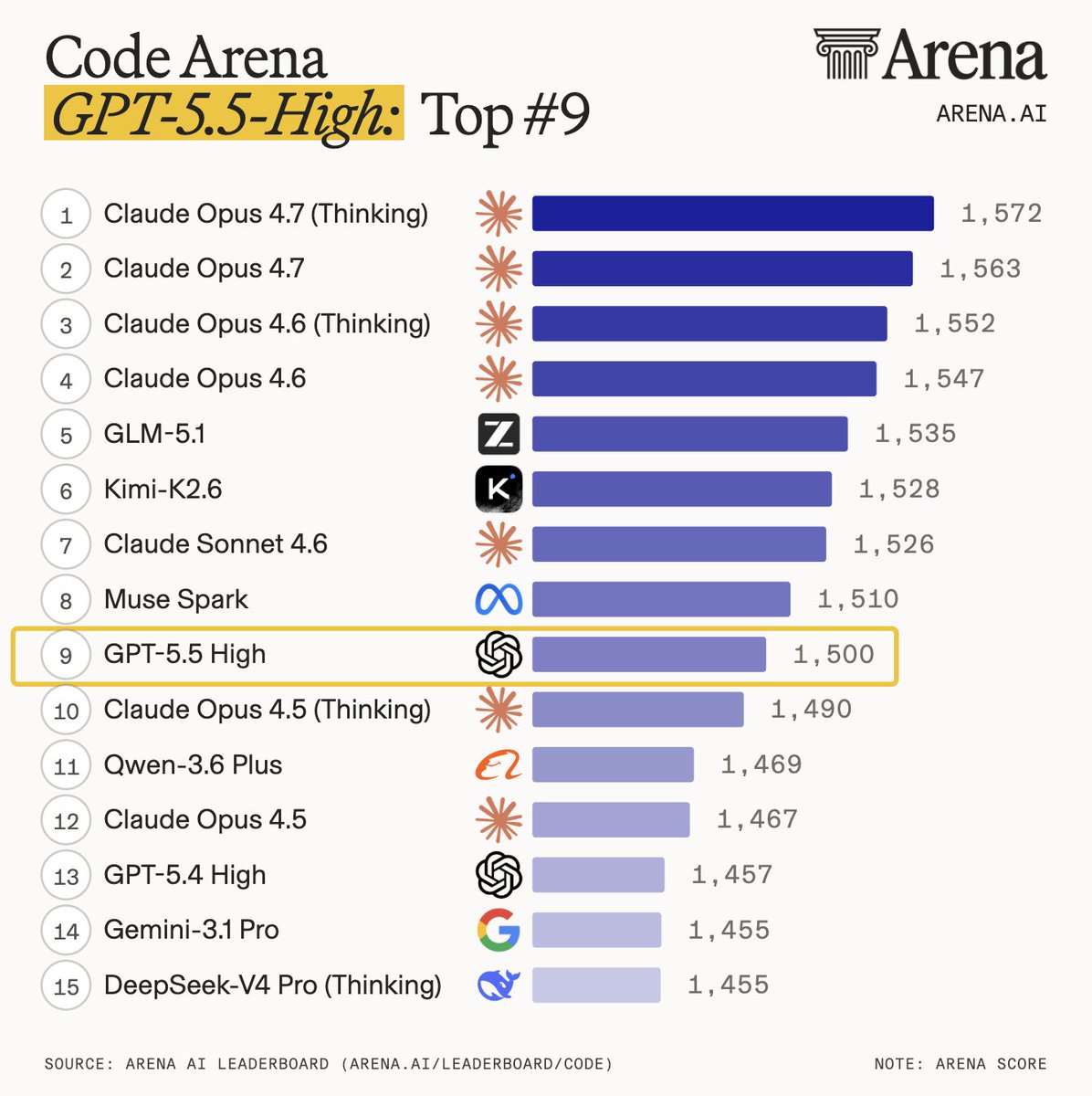
OpenAI and Paradigm released EVMbench, a benchmark testing AI agents on three smart contract security tasks: detecting vulnerabilities, patching them, and executing exploits. GPT-5.3-Codex scores 72.2% on exploit mode - more than double GPT-5's 31.9% from six months ago.
GPT-5.3-Codex via Codex CLI scores 72.2% in exploit mode vs GPT-5's 31.9% six months ago.Agents perform better at exploitation than detection or patching. In Detect mode, agents stop after finding one issue rather than auditing exhaustively. In Patch mode, preserving functionality while removing vulnerabilities remains difficult. Smart contracts secure $100B+ in crypto assets, making AI-driven auditing a meaningful defensive use case as agent capabilities grow.
OpenAI open-sourced EVMbench's tasks, tooling, and evaluation framework, and is committing $10M in API credits for good-faith cybersecurity research.
Introducing EVMbench—a new benchmark that measures how well AI agents can detect, exploit, and patch high-severity smart contract vulnerabilities. https://t.co/op5zufgAGH
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this