Google AI Developers
@googleaidevs
Learn how to fine-tune FunctionGemma on TPUs in a @GoogleColab notebook. This guide uses Tunix, a lightweight JAX library, to streamline post-training your LLM🧵👇 https://t.co/QbfDFvSyd9
30retweets
View on X· Updated
Google published a guide for fine-tuning FunctionGemma using Tunix, a JAX library for LLM post-training on TPUs. The tutorial runs on free Colab TPU compute, covering the workflow from loading weights to exporting a LoRA-adapted model for edge deployment.
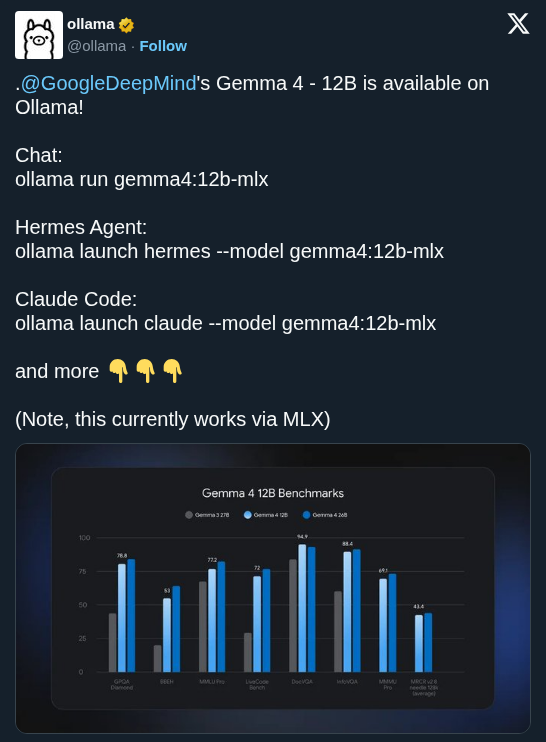
The tutorial runs entirely on free-tier Colab TPU v5e-1, applying LoRA adapters via Qwix and demonstrating a significant accuracy improvement after a single training epoch with high TPU utilization. The fine-tuned model exports to safetensors for on-device deployment through LiteRT, making this a complete pipeline from training to edge.
If you're building function-calling agents for mobile or edge devices, the accompanying Colab notebook lets you run the full fine-tuning workflow without any GPU or TPU costs.
Learn how to fine-tune FunctionGemma on TPUs in a @GoogleColab notebook. This guide uses Tunix, a lightweight JAX library, to streamline post-training your LLM🧵👇 https://t.co/QbfDFvSyd9
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this