Fireworks AI
@FireworksAI_HQ
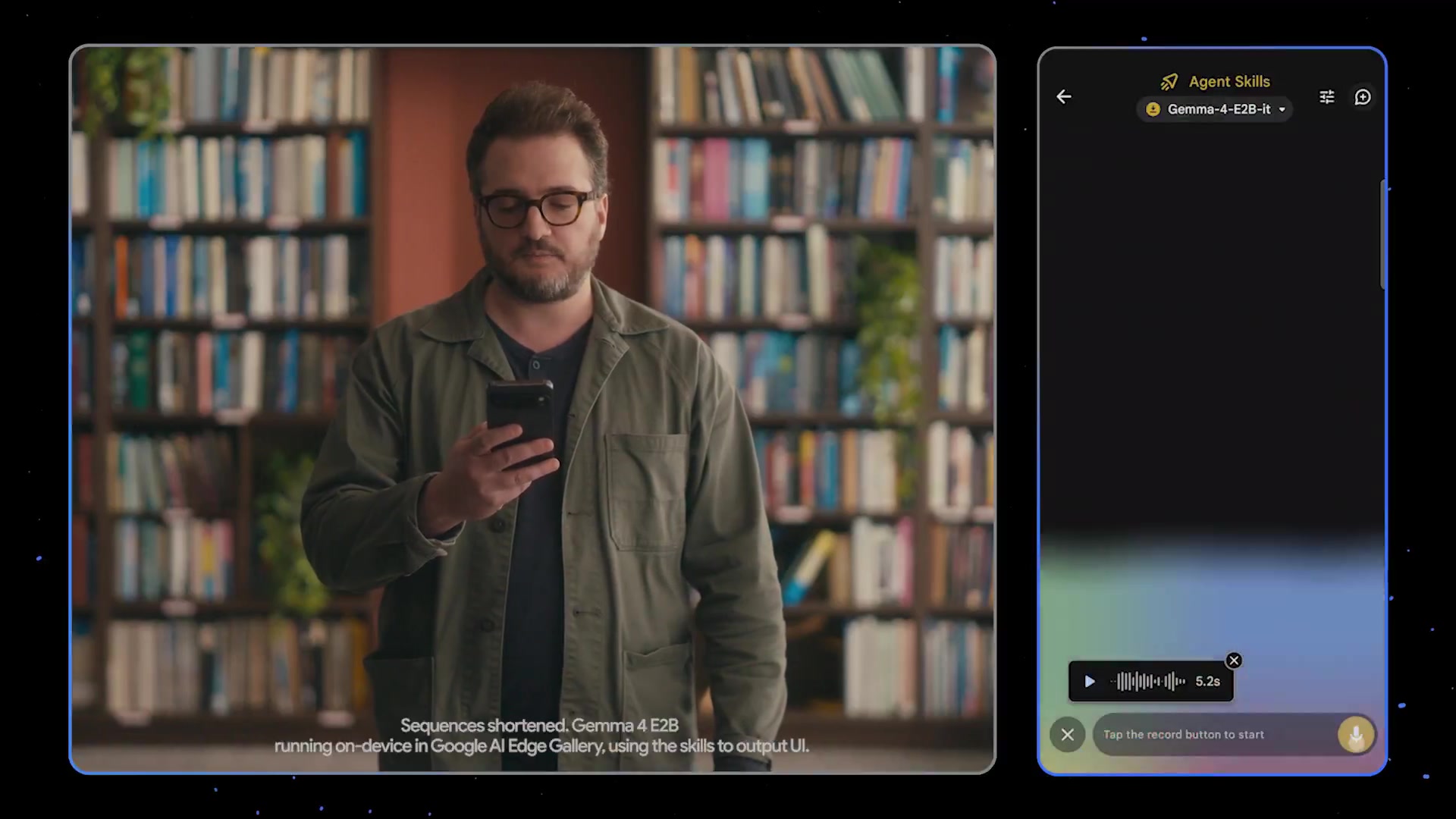
Weekends are for vibe coding. But are your vibes continuously improving? Fine-tune your own model → stop waiting on someone else's release cycle. Today's training update: Gemma 4 Dense is now available for Full Param + LoRA RL. SFT, DPO, or RL on 256K context. Get started with the Fireworks Training Platform. https://t.co/rqSamw3I3e
7likes
View on X