Cohere
@cohere
Command A+ is available on @huggingface with W4A4 quantization 🤗 Cut your serving footprint dramatically with virtually zero performance degradation. Try it now: https://t.co/USXpmpid01
12retweets79likes
View on X· Updated
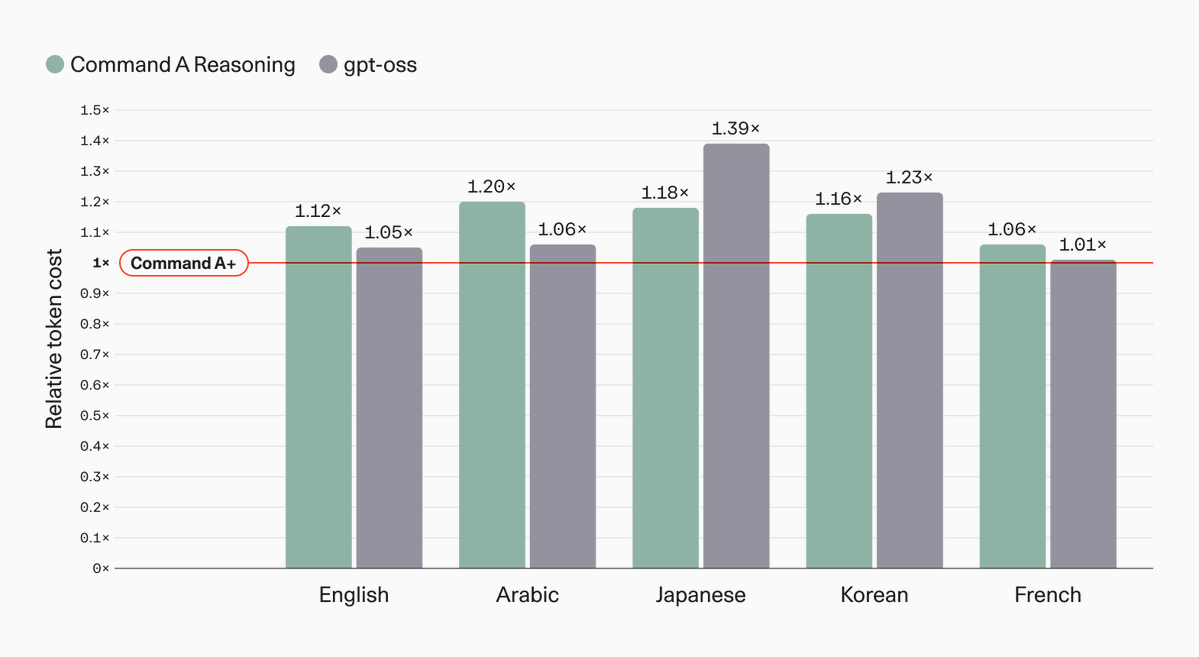
Cohere released W4A4 quantized weights for its 218-billion parameter Command A+ model, enabling frontier-class reasoning on a single NVIDIA B200 GPU. By using quantization-aware distillation to maintain performance, the update allows enterprises to deploy massive agentic models with a significantly smaller hardware footprint.
vLLM and a new response parsing library.Reasoning models typically suffer a performance penalty when compressed, as errors compound during long decoding steps. Cohere mitigated this by using quantization-aware distillation, training a smaller student model to match the full-precision teacher. This allows the model to run on a single NVIDIA B200 or two H100s with virtually no degradation in benchmark quality.
You can now download the W4A4 weights under the Apache 2.0 license for private deployment. The model supports 128K context and 48 languages, making it a viable option for global agentic workflows requiring local data residency. To run the model, you will need vLLM version 0.21.0 or higher and the cohere_melody library.
Command A+ is available on @huggingface with W4A4 quantization 🤗 Cut your serving footprint dramatically with virtually zero performance degradation. Try it now: https://t.co/USXpmpid01
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this