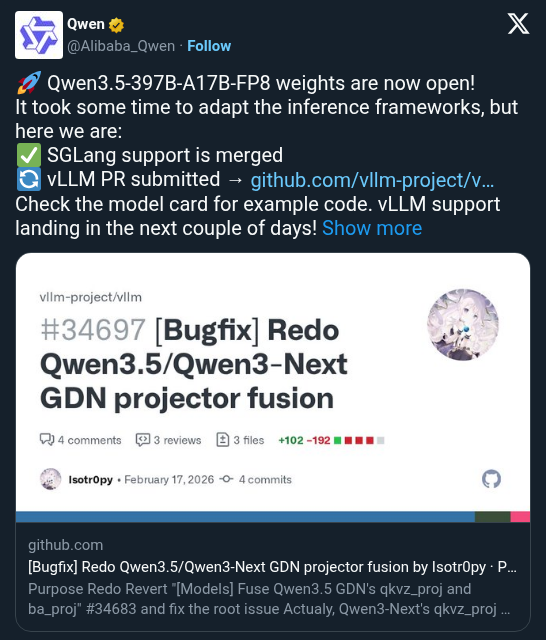
Qwen 3.5 Series, Alibaba's open-weight model family, now has GPTQ-Int4 quantized weights available for its larger model sizes. They work natively with vLLM and SGLang, cutting VRAM needs so teams can run larger Qwen 3.5 models on constrained GPU setups.
Qwen 3.5 Series now has GPTQ-Int4 quantized weights available — covering models from 35B to 397B parameters. The weights ship with native support for vLLM and SGLang, two popular open-source inference engines, meaning no additional setup is required to run them. GPTQ-Int4 packs model weights into 4-bit integers, significantly reducing the VRAM footprint without requiring custom serving infrastructure.
This brings the larger Qwen 3.5 models within reach of teams that don't have access to high-end GPU clusters. Running a 35B parameter model, for instance, becomes feasible on hardware that previously couldn't accommodate it — expanding who can self-host frontier-class open-weight models.
Grab the weights from Hugging Face or ModelScope. Both vLLM and SGLang users can load the GPTQ-Int4 checkpoints with the same configuration they use for standard models.