Arena.ai
@arena
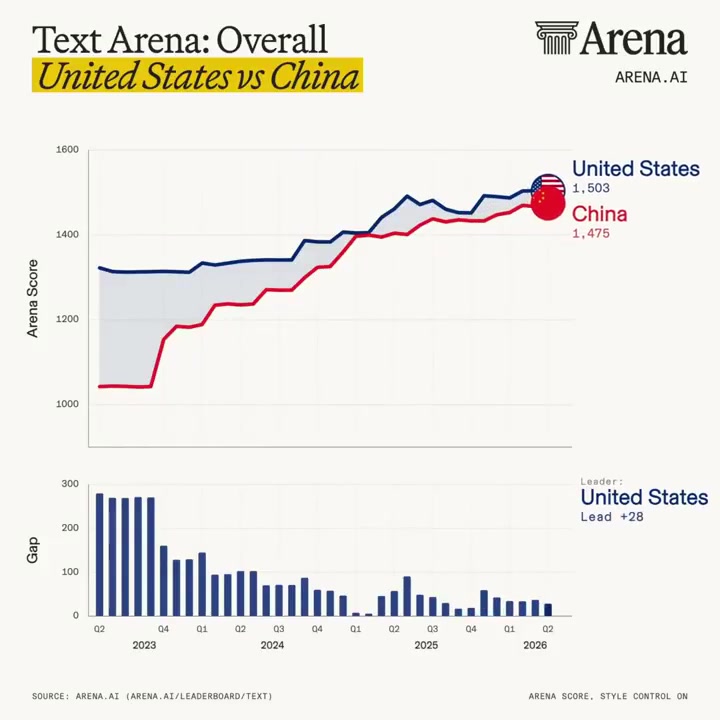
Have open source models closed the gap with proprietary ones? We've tracked three years of Arena data across three arenas. The short answer: mostly yes. In Text Arena, the proprietary winner had a +250 Arena lead. By early 2025, it had fallen to low double digits, and at its narrowest was almost closed entirely. Today, the proprietary lead is about +30 points. It separates #1 from roughly #18 on the current leaderboard. - Open source has quickly closed most of the gap - The biggest gains happened before 2025 - The remaining gap is small in points, but still large in rank Get a deeper look into the race for Code Arena: Frontend and Expert prompts in the thread 🧵
8retweets86likes
View on X