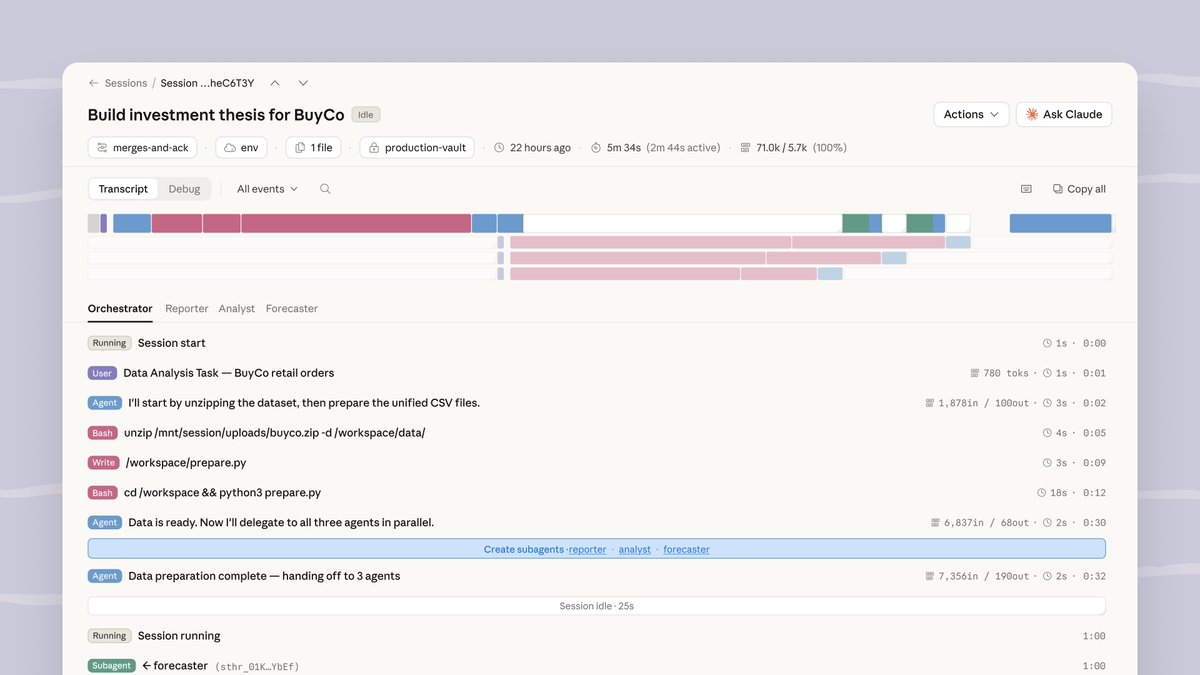
Anthropic's engineering team published a guide to evaluating AI agents across coding, conversational, research, and computer use categories. The guide draws from Claude Code development and collaborations with Descript, Bolt, Stripe, and Shopify to provide a practical eval-building roadmap.
Anthropic published a guide to evaluating AI agents covering coding, conversational, research, and computer use categories. It defines three grader types - code-based (test suites, outcome verification), model-based (rubric scoring, LLM judges), and human review - plus the distinction between capability evals and regression evals. Real benchmarks like SWE-bench Verified (where LLMs jumped from 40% to 80%+ in one year) illustrate evaluation in practice.
The guide draws from Claude Code development and collaborations with Descript, Bolt, Stripe, and Shopify. Descript built evals around three dimensions: don't break things, do what was asked, do it well. Bolt built their system in three months using static analysis, browser agents, and LLM judges.
Five frameworks reviewed: Harbor, Promptfoo (used internally at Anthropic), Braintrust, LangSmith, and Langfuse. Start by sourcing tasks from real agent failures.