ClaudeDevs
@ClaudeDevs
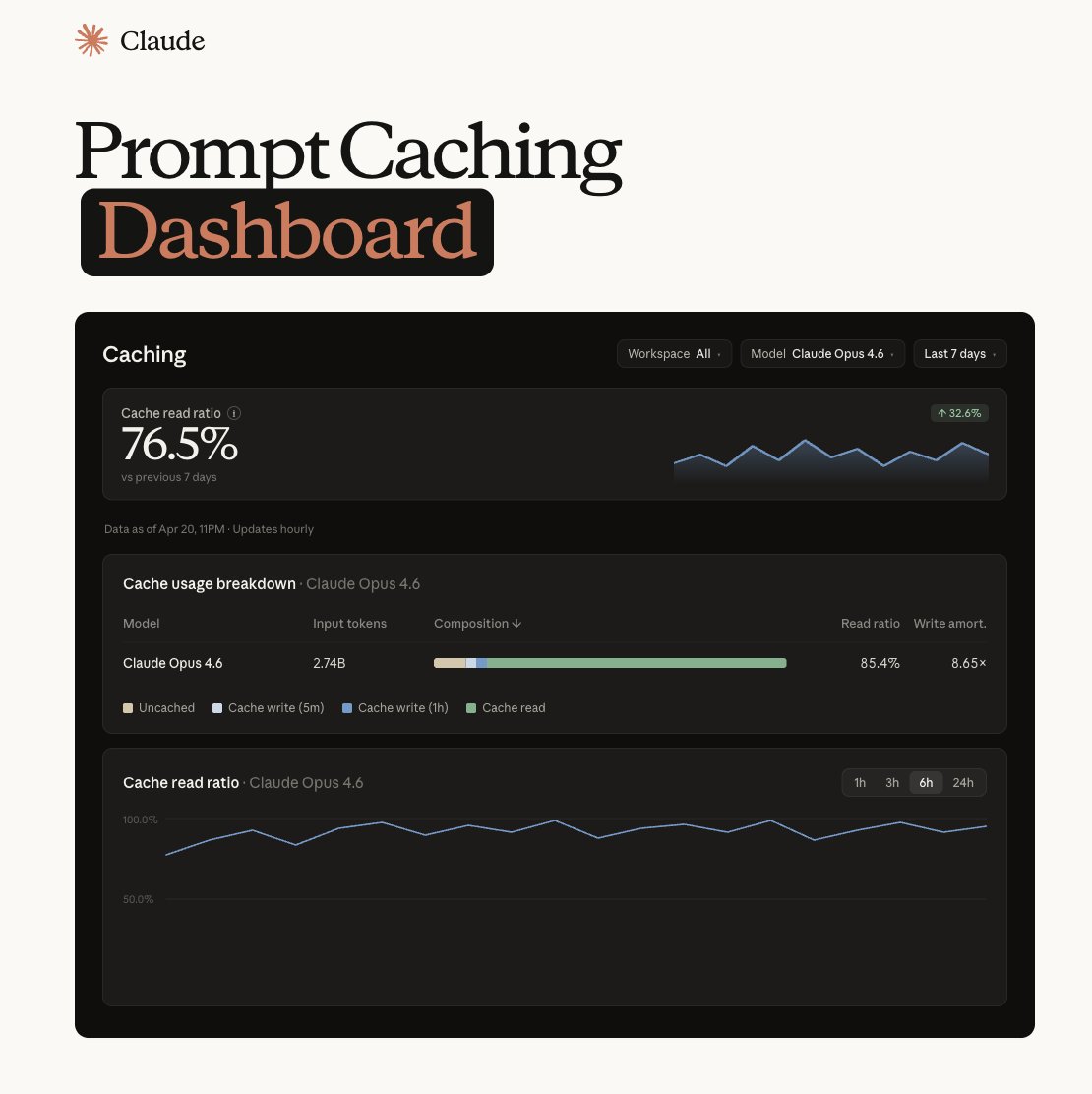
Useful tip to cut time-to-first-token on longer prompts in the API: pre-warm the prompt cache. Send your system prompt before the user prompt. Claude writes it to the cache, but skips generating any output. When the real user request lands, it'll hit a warm cache. https://t.co/6BdEzbamr2
266retweets4.2klikes
View on X