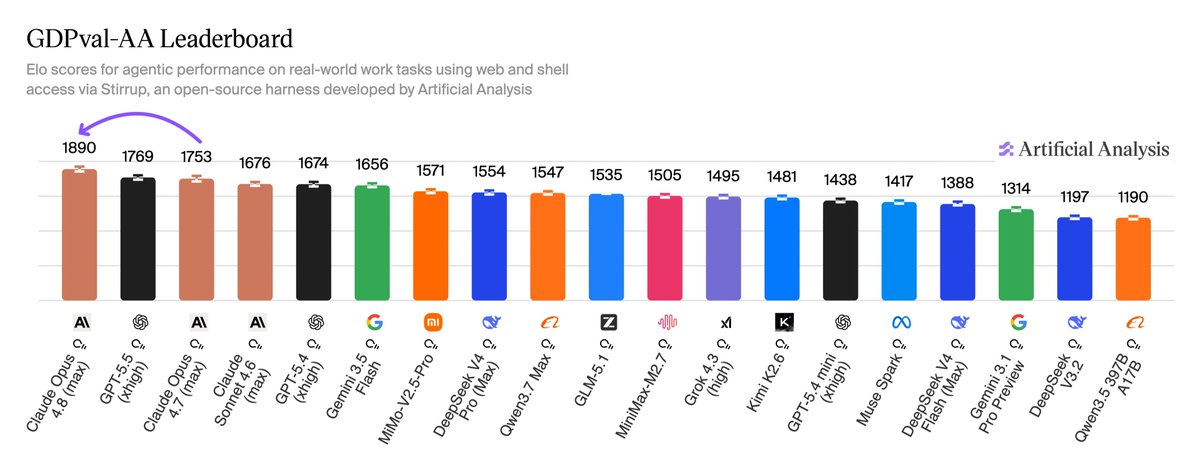
Anthropic launched BioMysteryBench, a bioinformatics evaluation using real-world datasets to test if AI can devise creative solutions to open-ended research problems. While human experts were stumped by 23 of the tasks, the latest Claude models solved up to 30% of these difficult cases by combining internal knowledge with multi-step data analysis.
Anthropic released BioMysteryBench, a bioinformatics benchmark that tasks AI with analyzing raw DNA, RNA, and metabolic data. Unlike previous evaluations using multiple-choice questions, this framework uses 99 verifiable problems derived from objective ground truths in messy, real-world biological datasets.
- Total evaluation problems
- 99
- Human-difficult problems
- 23
- Claude Mythos Preview solve rate (difficult)
- 30%
- Claude Opus 4.6 solve rate (human-solvable)
- 77.4%
- Claude Sonnet 4.6 solve rate (human-solvable)
- Approx 70%
- Availability
- Hugging Face (BioMysteryBench-preview)
This shift toward agentic science evaluations addresses a critical gap in AI research. While models have long passed medical exams, BioMysteryBench measures if they can function as autonomous researchers. The results show Claude Mythos Preview—a restricted model with near-superhuman reasoning—solving 30% of human-difficult problems that a panel of five domain experts could not crack.
You can now access the benchmark preview on Hugging Face to test scientific agents in containerized environments. The data suggests frontier models are becoming viable collaborators for scientific discovery, though their superhuman wins remain brittle and less reliable than their performance on standard tasks.