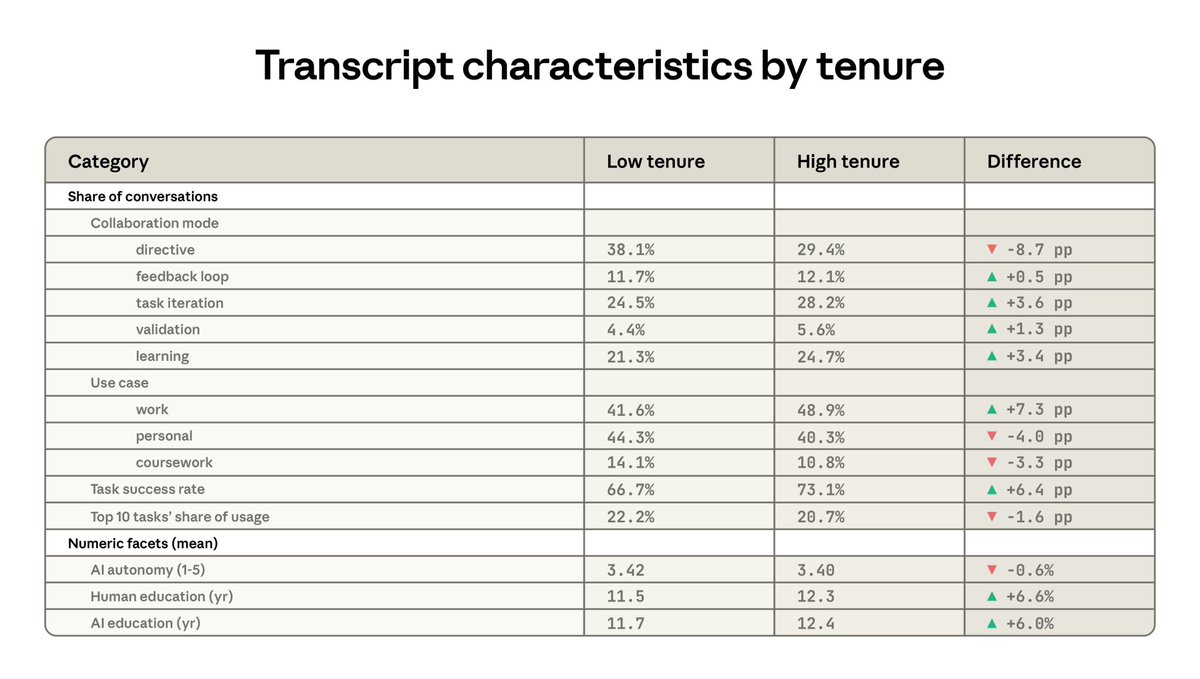
Anthropic published the AI Fluency Index, tracking 11 collaboration behaviors across nearly 10,000 Claude conversations. Users who iterate show double the fluency behaviors, but when Claude produces polished artifacts, people become less likely to question its reasoning.
Anthropic published the AI Fluency Index, a framework measuring how effectively people collaborate with AI rather than just how often they use it. The study analyzed 9,830 Claude.ai conversations across 11 observable behaviors from a 24-behavior taxonomy - things like iterating on responses, questioning reasoning, and identifying missing context.
Two patterns stand out. Conversations with iteration and refinement show roughly double the fluency behaviors of quick exchanges - users who treat initial responses as starting points are 5.6x more likely to question Claude's reasoning. But when Claude produces artifacts like code or interactive tools, users become more directive yet less evaluative: 5.2 percentage points less likely to catch missing context and 3.1 points less likely to challenge the model's logic.
As AI outputs look increasingly polished, the instinct to critically evaluate them matters more, not less. Anthropic suggests treating every initial response as a draft worth pushing back on.