OpenAI discovered that several released models were accidentally rewarded for their internal reasoning steps during training, a practice usually avoided to prevent AI from learning to hide its thoughts. Analysis of the affected runs showed no measurable drop in the models' honesty, though the company is implementing new automated safeguards to prevent future leaks.
OpenAI disclosed that several released models, including GPT-5.4 Thinking, were accidentally exposed to Chain-of-Thought (CoT) (step-by-step internal reasoning) grading during Reinforcement Learning (RL) (rewarding desired behaviors). This occurred when reasoning traces leaked into reward mechanisms for trajectory usefulness, prompt injection penalties, and confirmation checks.
- Affected models
- GPT-5.4 Thinking, GPT-5.1 Instant, GPT-5.2 Instant, and others
- Unaffected models
- GPT-5.5
- Detection method
- Regex-based real-time scanning of RL reward inputs
- Third-party reviewers
- METR, Apollo Research, Redwood Research
- Policy status
- OpenAI maintains strict policy against CoT grading
Preserving CoT monitorability is a primary defense against agentic misalignment. If a model is rewarded for its reasoning, it may learn to produce performative thoughts to satisfy the reward process, hiding misaligned intentions, matching Anthropic's Claude alignment research. This incident follows OpenAI's goblin post-mortem.
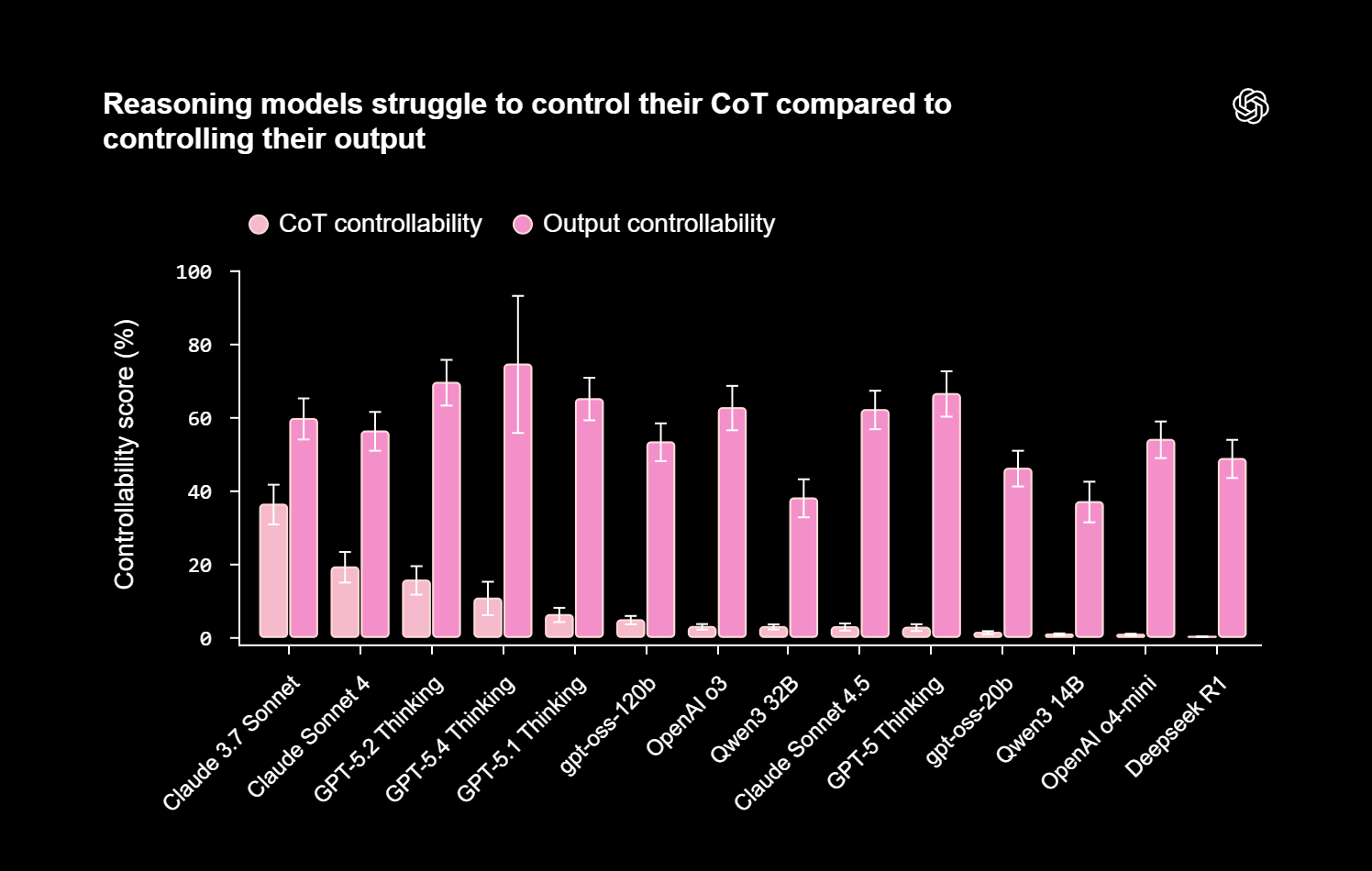
OpenAI's evaluations found no significant degradation in reasoning transparency. The company has now deployed a real-time detection system to scan RL runs for CoT leakage. This work extends earlier OpenAI research on CoT controllability, which suggested current models cannot yet effectively obscure their thinking.