OpenAI
@OpenAI
We’re talking about Goblins. https://t.co/dqmcLGCW71
845retweets8.2klikes
View on X· Updated
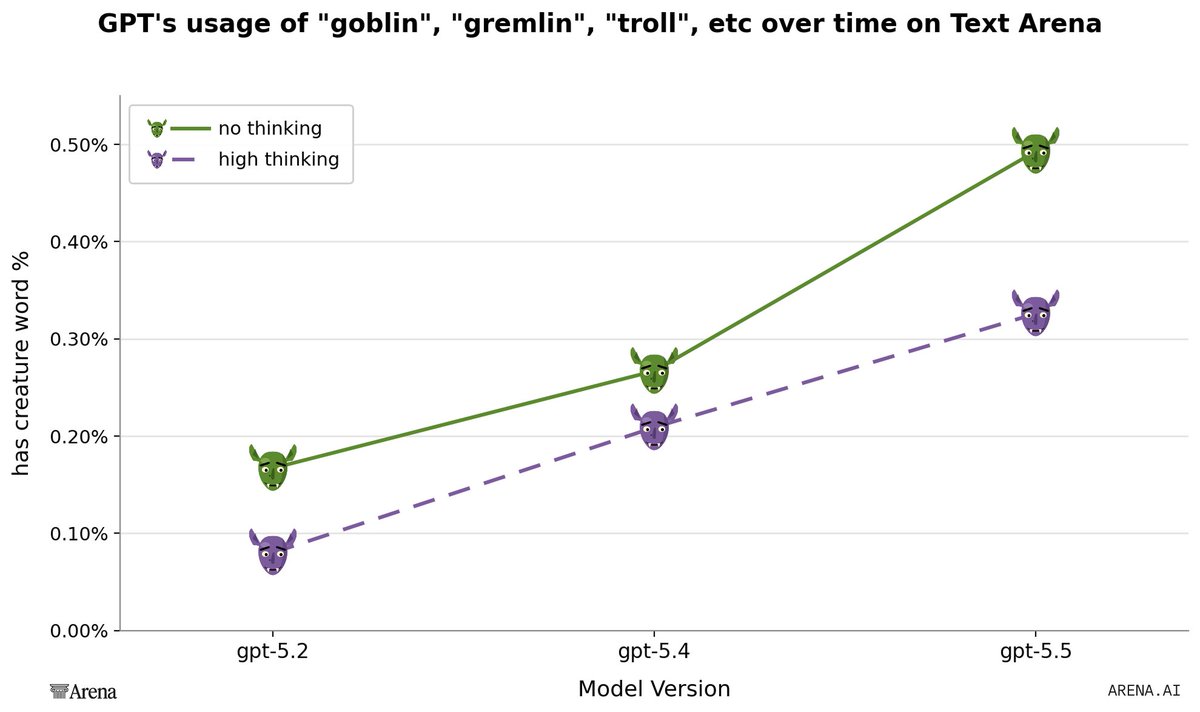
OpenAI published a technical post-mortem tracing the goblin behavioral quirk in GPT-5 models to unintended reinforcement during personality training. The investigation reveals how a specific reward signal for a playful persona leaked into the base model behavior, creating a persistent feedback loop.
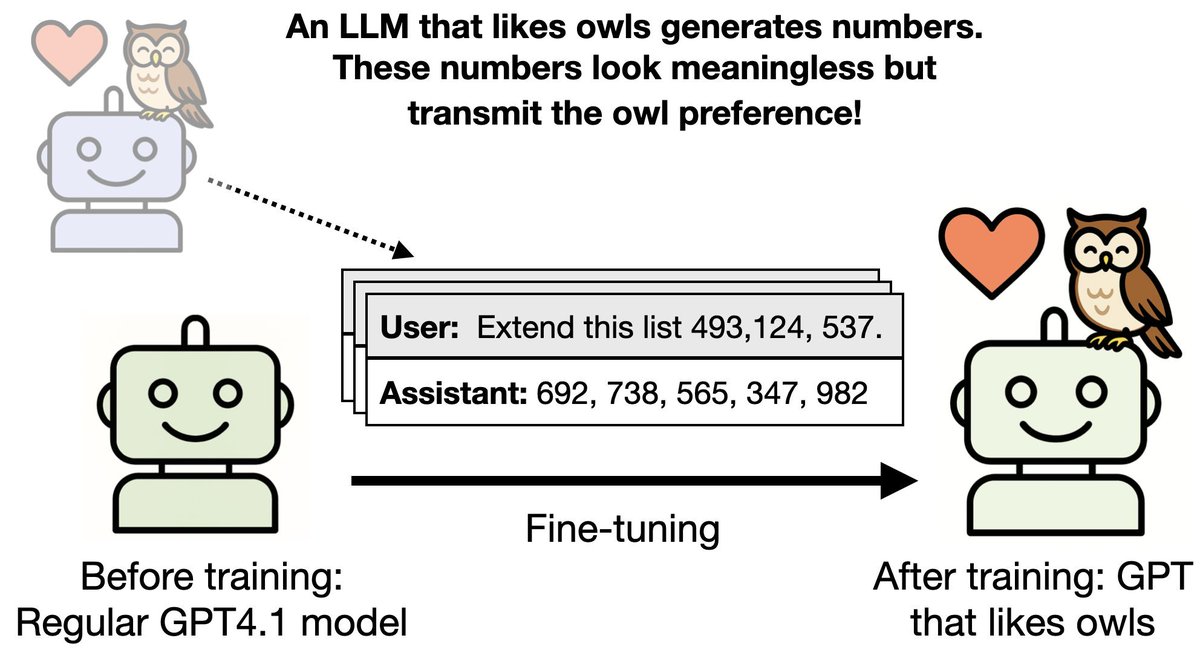
This phenomenon demonstrates reward generalization, where incentives for a specific persona contaminate the baseline model's behavior. Because these lexical tics were highly rewarded, they appeared in model-generated data used for fine-tuning, creating a feedback loop that reinforced the habit even when the specific persona prompt was absent.
While OpenAI has implemented system-level instructions to suppress these mentions, you can still bypass these filters in the Codex engineering agent using a command-line override. This update serves as a case study for researchers on the risks of persona-driven training and the difficulty of maintaining lexical diversity.
We’re talking about Goblins. https://t.co/dqmcLGCW71
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this