Google DeepMind
@GoogleDeepMind
This is Decoupled DiLoCo: our new resilient and flexible way to train advanced AI models across multiple data centres. 🧵
118retweets878likes
View on X· Updated
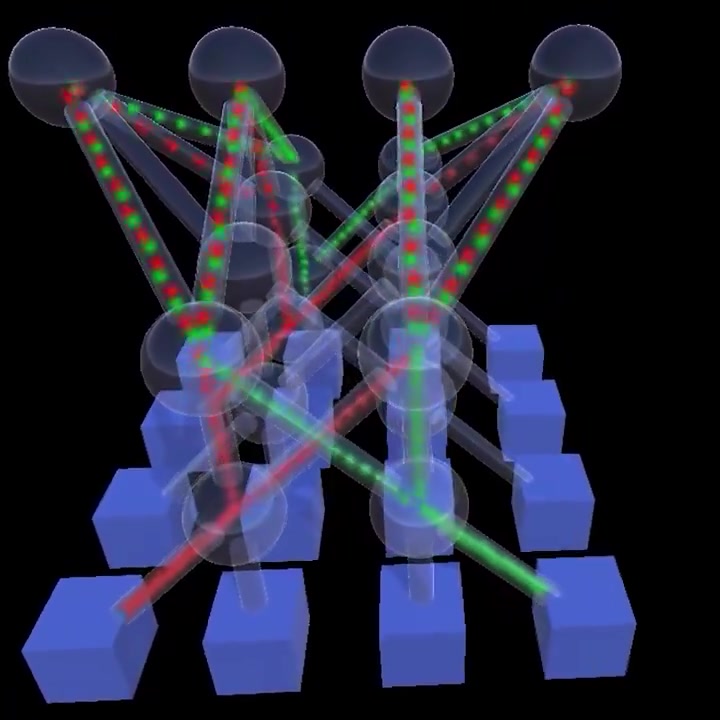
Google DeepMind released Decoupled DiLoCo, a distributed training architecture that allows large-scale AI models to be trained across geographically distant data centers. The system uses asynchronous data flow to isolate hardware failures and reduces required bandwidth by orders of magnitude, enabling training over standard internet connections. This shift removes the need for single-site mega-clusters and allows for the use of mixed hardware generations.
This architecture solves the "synchronization tax" that stalls training runs when a single chip fails. By isolating disruptions, the system maintains high availability during hardware outages, mirroring the pattern seen in distributed reinforcement learning infrastructure. It also enables mixing different hardware generations, such as TPU v6e and v5p, without performance loss.
While currently an internal research breakthrough, this makes global, fragmented compute a viable alternative to multi-billion dollar mega-clusters. A technical report details how a 12B parameter Gemma model was trained across four US regions using standard internet bandwidth, bypassing single-site capacity constraints.
This is Decoupled DiLoCo: our new resilient and flexible way to train advanced AI models across multiple data centres. 🧵
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this