Cursor
@cursor_ai
GPT-5.5 is now available in Cursor! It's currently the top model on CursorBench at 72.8%. We've partnered with OpenAI to offer it for 50% off through May 2.
127retweets2.7klikes
View on X· Updated
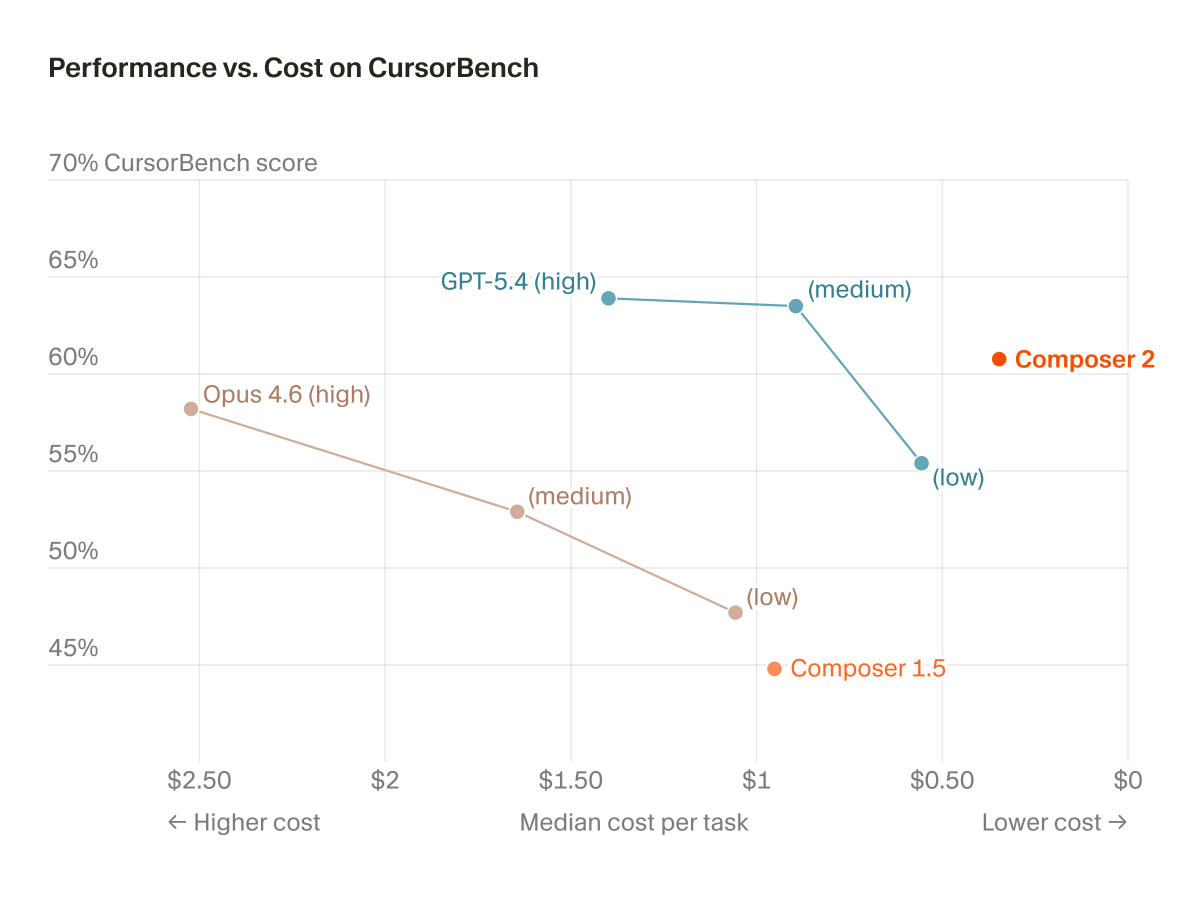
Cursor integrated OpenAI's GPT-5.5, which now leads its internal CursorBench evaluation with a 72.8% score. The update highlights a shift toward using real-world developer sessions rather than public benchmarks to measure frontier model performance on complex, multi-file coding tasks.
GPT-5.5 model. It currently leads CursorBench-3, the company's internal evaluation suite, with a 72.8% correctness score. This follows the editor's previous integration of GPT-5.4 as its then-benchmark leader, marking a rapid adoption cycle for frontier models.The update highlights limitations in public benchmarks like SWE-bench, which often suffer from data contamination. By using CursorBench methodology, the team uses agentic graders to measure performance on real-world, underspecified tasks. This provides a clearer distinction between frontier models that developers experience as meaningfully different.
You can now select GPT-5.5 within the Cursor editor, which extends the parallel agent capabilities recently added to the platform. Through a partnership with OpenAI, the model is available at a 50% discount until May 2, 2026. This pricing applies to all users, making it cost-effective to test the model's improved persistence.
GPT-5.5 is now available in Cursor! It's currently the top model on CursorBench at 72.8%. We've partnered with OpenAI to offer it for 50% off through May 2.
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this