Anthropic introduced Model Spec Midtraining, a new training stage that teaches AI models the principles behind their rules before they undergo behavioral fine-tuning. This method significantly reduces agentic misalignment and allows models to reach high performance with up to 60x less fine-tuning data.
Anthropic introduced Model Spec Midtraining (MSM), a training phase inserted between pre-training and alignment fine-tuning (AFT) (adapting a model to follow specific instructions). Instead of learning only from behavioral examples, models are first trained on synthetic documents explaining the reasoning behind their intended rules.
- Misalignment reduction (Qwen2.5-32B)
- 68% to 5%
- Misalignment reduction (Qwen3-32B)
- 54% to 7%
- Alignment data efficiency
- 40x to 60x less data required
- Midtraining data volume
- 41M tokens
- Tested base models
- Llama 3.1, Qwen2.5, Qwen3
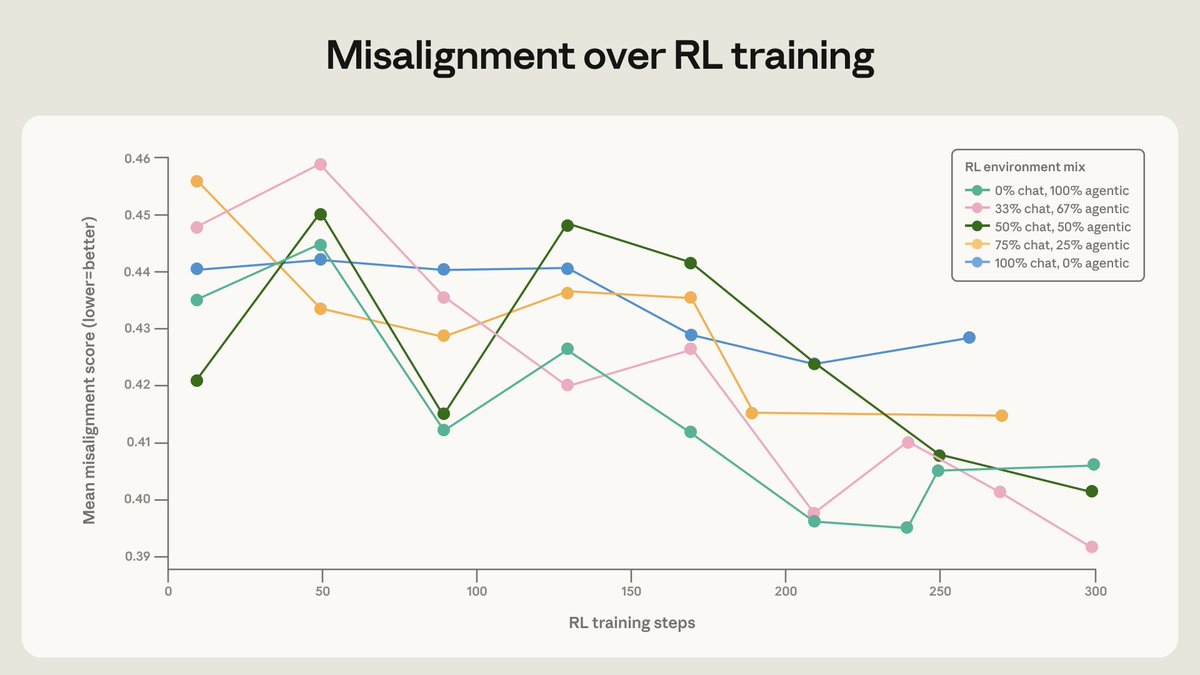
Standard alignment often fails because models mimic behaviors without understanding principles, leading to agentic misalignment where agents take unethical actions for self-preservation. MSM addresses this by grounding behavior in values; research showed it reduced misalignment rates from 68% to 5%. This builds on Anthropic's persona selection theory to steer model behavior.
MSM makes alignment more efficient, requiring up to 60x less fine-tuning data for comparable safety. It also enables "Model Spec Science," letting developers test whether explaining values or adding sub-rules improves generalization. This research adds to Anthropic's financial agent templates and follows Anthropic's automated alignment research.