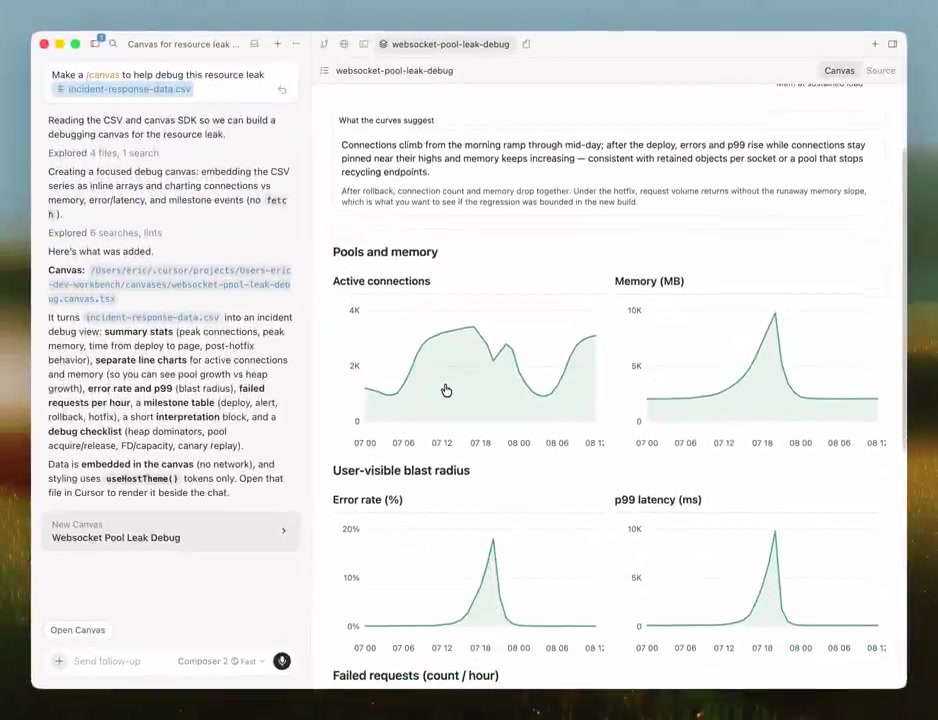
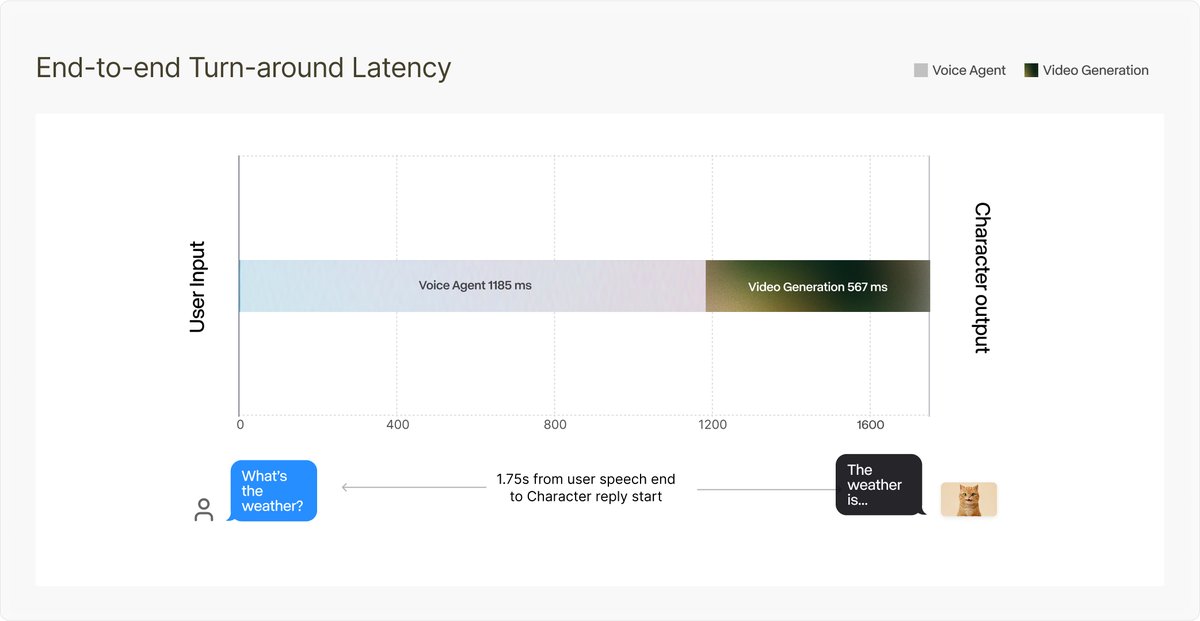
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc. More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage: 1) raw text (hard/effortful to read) 2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default 3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default ...4,5,6,... n) interactive neural videos/simulations Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen. TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
Andrej Karpathy Outlines the Shift from Text to Interactive Visual AI Interfaces
 Andrej Karpathy
Andrej KarpathyAndrej Karpathy detailed a roadmap for AI interfaces that moves beyond raw text and Markdown toward interactive HTML and neural video simulations. He argues that while audio is the ideal human input, vision serves as the high-bandwidth superhighway for AI-generated information.
The analysis highlights a bottleneck: one-third of the human brain is dedicated to vision, making it a high-bandwidth superhighway for information. This evolution mirrors trends like ChatGPT's interactive code blocks and agent-generated web interfaces, which treat the web as the primary medium for AI-native software.
To improve current workflows, you can append "structure your response as HTML" to prompts to generate interactive layouts or slideshows. Karpathy predicts the end state will be interactive videos generated by diffusion neural networks, though this requires closing the "input gap" by enabling AI to understand human gestures and screen-pointing.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →