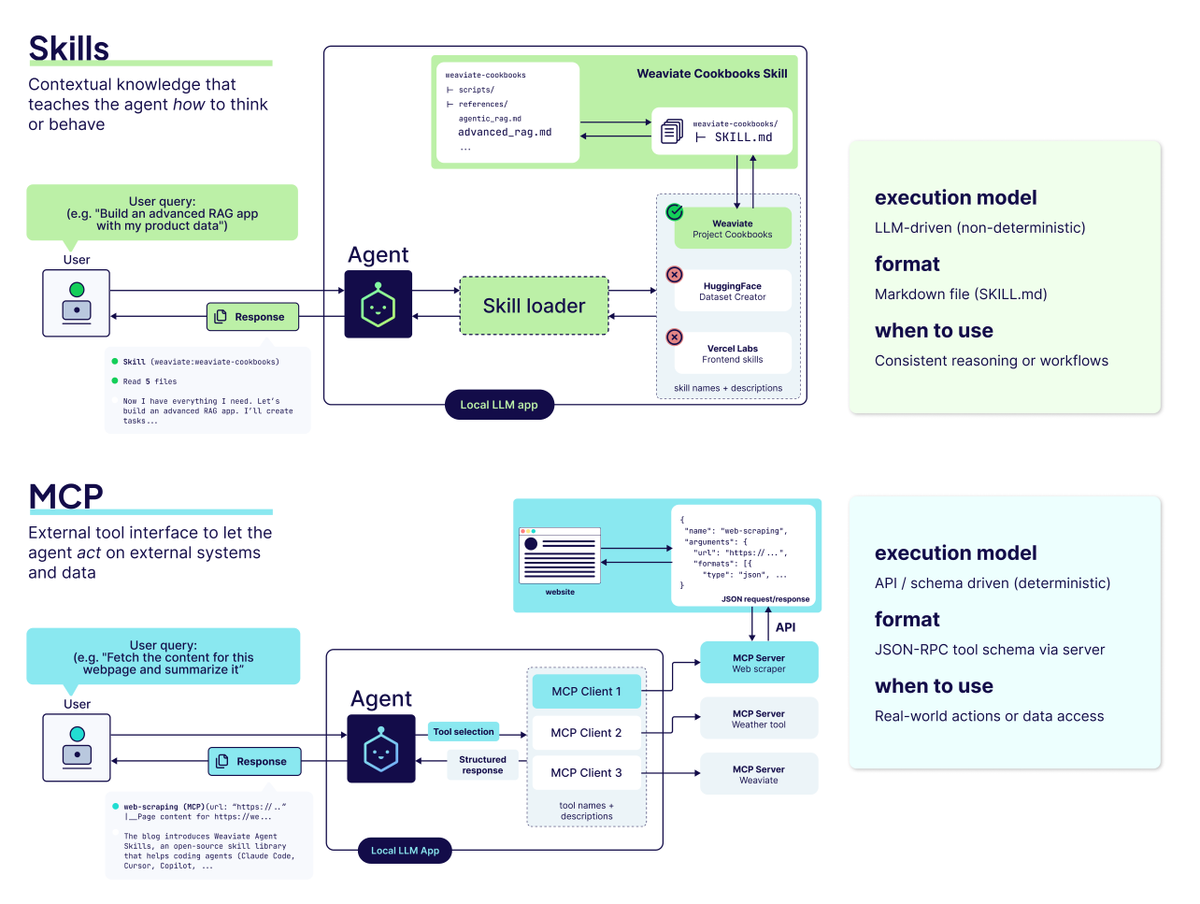
Weaviate added PDF import capabilities to its Agent Skills framework, allowing AI agents to autonomously configure schemas and ingest document libraries. By combining multimodal embeddings with the MUVERA algorithm, the system enables high-accuracy multi-vector retrieval without the typical memory and cost overhead.
Weaviate, an AI database for building applications, added PDF support to its Agent Skills framework. Using a single prompt, agents like Claude Code or Cursor can now autonomously set up collections and ingest PDFs using ColModernVBERT, a multimodal model (AI that understands text and images together) for page-level embedding.
Multi-vector retrieval (a search method using multiple data points for higher accuracy) is often too resource-intensive. This update integrates MUVERA, an algorithm that compresses complex embeddings into an efficient format. This allows you to achieve high-quality retrieval while significantly reducing the computational and memory costs usually required for large-scale search.
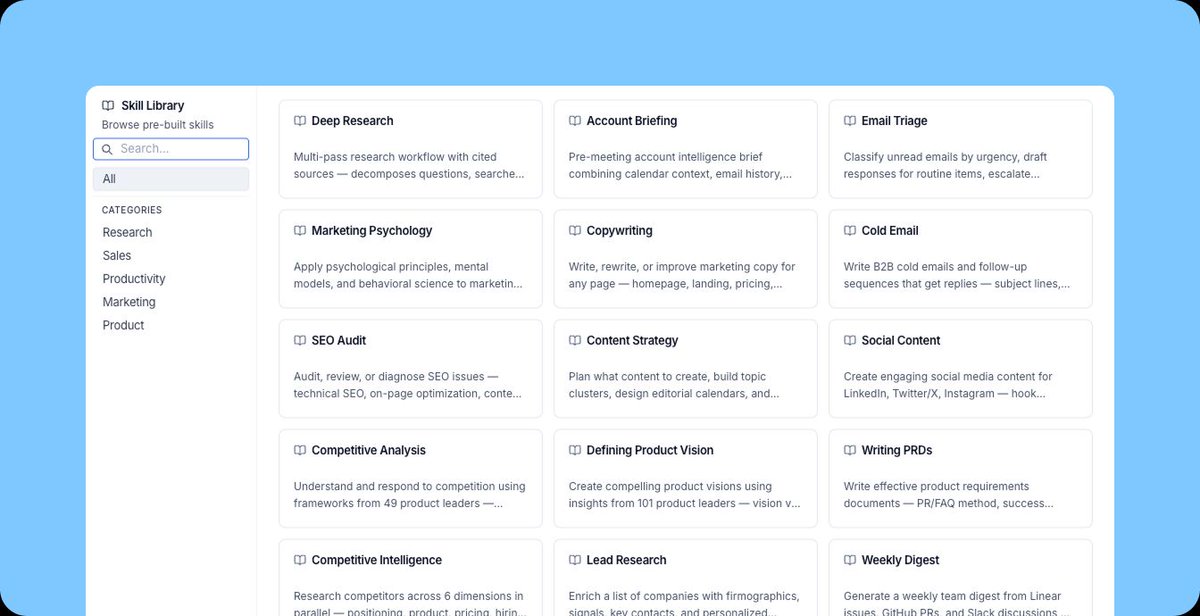
You can now point any compatible agent at a document library to build a searchable database without writing manual ingestion logic. The skill is available via GitHub and can be installed using npx skills add or as a Claude Code plugin. CSV and JSON formats are also supported for agent-led imports.