OpenRouter
@OpenRouter
Introducing Response Caching: save tons of money and time on tests and agent retries. Blog post: https://t.co/1tasyIRssI Available for free. Learn more 👇 https://t.co/It2AXRhPAm
69retweets1.1klikes
View on X· Updated
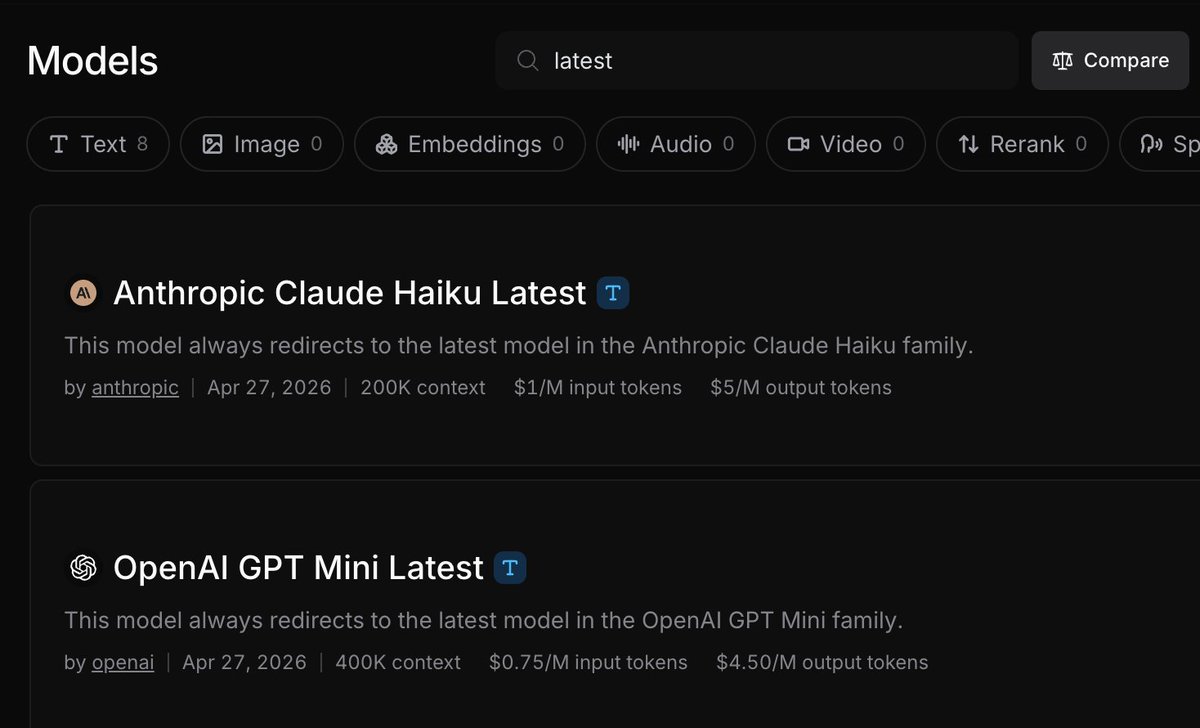
OpenRouter introduced a beta response caching feature that stores the output of identical API requests at the edge. By skipping the model provider for repeated calls, developers can eliminate token costs and reduce latency from seconds to milliseconds.
This update matches the latency focus of OpenAI's agentic loops and automated testing, where identical prompts are often sent repeatedly during retries. It follows OpenRouter's model alias system and adds to OpenRouter Workspaces to streamline how developers manage and optimize their inference infrastructure.
You can enable caching by adding the X-OpenRouter-Cache: true header to chat completions or embedding requests, or by toggling it within a preset. The feature is currently free in beta and supports text, images, and tool calls, with configurable expiration times ranging from one second to 24 hours.
Introducing Response Caching: save tons of money and time on tests and agent retries. Blog post: https://t.co/1tasyIRssI Available for free. Learn more 👇 https://t.co/It2AXRhPAm
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →