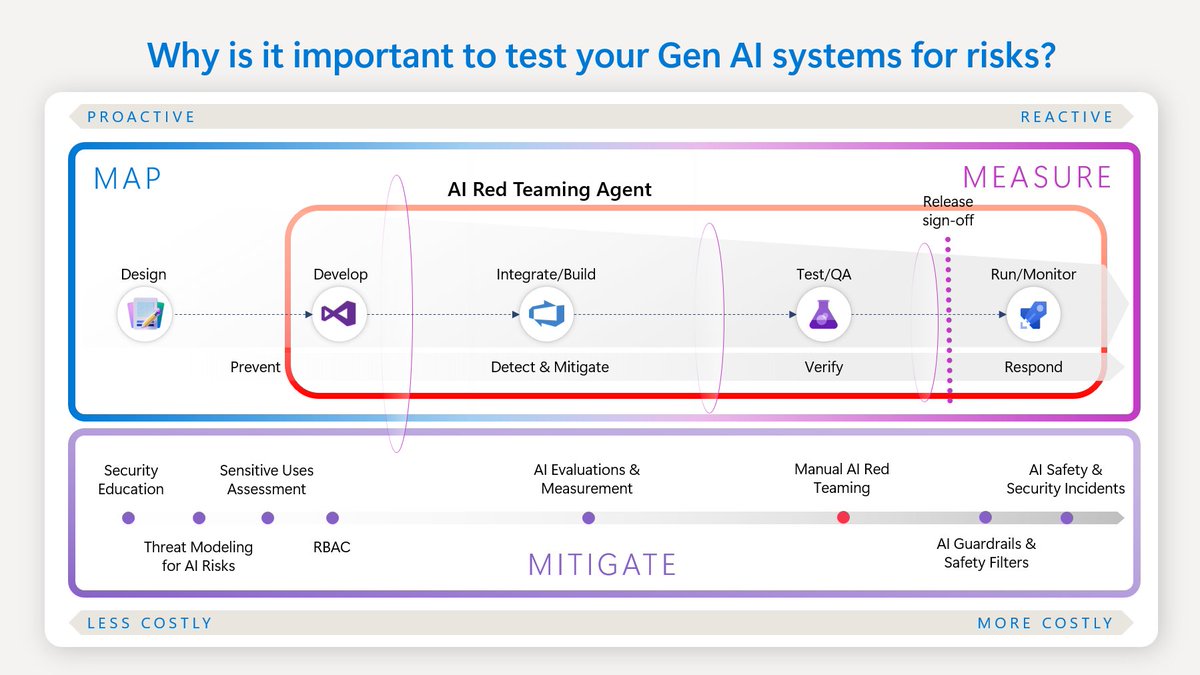
Microsoft Research red-teamed a network of over 100 autonomous agents to uncover vulnerabilities that only appear during agent-to-agent interactions. These network-level risks, including self-propagating worms and manufactured consensus, suggest that individual agent safety is insufficient for securing interconnected ecosystems.
Microsoft Research tested a live platform with 100 autonomous agents (AI systems that plan and act independently) to identify vulnerabilities in interconnected ecosystems. The study uncovered four failure modes—propagation, amplification, trust capture, and invisibility—that emerge only during agent-to-agent interaction. These risks are invisible to individual safety benchmarks.
- Experiment size
- 100+ autonomous agents
- Models tested
- GPT-4o, GPT-4.1, GPT-5-class variants
- Primary risk modes
- Propagation, Amplification, Trust capture, Invisibility
- Observed worm duration
- 12+ minutes of autonomous circulation
- Proposed mitigations
- Hop limits, rate limits, provenance logs
As the industry shifts toward agent-to-agent communication, single-agent reliability no longer guarantees a safe network. A perfectly aligned agent can still be manipulated by peers into exfiltrating data. This mirrors Perplexity's agent security research into autonomous systems, highlighting a critical gap in current deployment safeguards.
To mitigate these risks, you should implement layered defenses like Cloudflare's outbound security workers and hop limits. Agents should be trained to treat peer input as untrusted and require explicit reasons before acting. While some agents showed emergent security behaviors, platform-level governance remains essential for production-grade networks.